Rozkład Dirichleta
Często tworzę dla studentów zadania za pomocą pakietu R-exams. Jest on wygodny, ponieważ pozwala generować zadania o tej samej treści, w których zmieniają się jedynie niektóre fragmenty, głównie liczby.
Oto przykład prostego zadania, które tworzę za pomocą R-exams:
Pewna zmienna losowa X przyjmuje przyjmuje trzy wartości:
1z prawdopodobieństwem0,227z prawdopodobieństwem0,518z prawdopodobieństwem0,27Wartość oczekiwana zmiennej X to:
Wariancja zmiennej X to:
Próbując stworzyć takie zadanie, w którym zamiast 1, 7, 8, 0,22, 0,51 i 0,27 generowałyby się losowo inne liczby, natrafiłem na prosty sposób generowania rozkładów prawdopodobieństwa: rozkład Dirichleta.
O rozkładzie Dirichleta można przeczytać na Wikipedii. Tutaj opiszę, w jaki sposób stosując rozkład Dirichleta, można uzyskać losowy dyskretny rozkład prawdopodobieństwa. W tym celu używamy funkcji rdirichlet z pakietu gtools:
library(gtools)
rdirichlet(n = 3, alpha = c(1,1,1,1))
## [,1] [,2] [,3] [,4]
## [1,] 0.1942181 0.08618226 0.45579746 0.2638022
## [2,] 0.3126603 0.33254773 0.03485169 0.3199403
## [3,] 0.1109524 0.19199674 0.37307295 0.3239779
Funkcja rdirichlet losuje wektory, których składowymi są ułamki z przedziału od 0 do 1, sumujące się do jedności (czyli prawdopodobieństwa). Ma ona dwa argumenty:
-
nto liczba wektorów (rozkładów prawdopodobieństwa), które chcemy wygenerować. W powyższym przykładzie generujemy trzy wektory o czterech składowych każdy. -
alphato wektor zawierający parametry koncentracji. Parametrów koncentracji powinno być tyle, ile chcemy mieć składowych (prawdopodobieństw). W powyższym przykładzie podano cztery parametry, co spowodowało, że wygenerowane wektory mają po cztery składowe (rozkłady prawdopodobieństwa są czteropunktowe).
Parametry koncentracji w powyższym kodzie są ustawione na 1, co daje równomierny rozkład prawdopodobieństw. To, że rozkład jest równomierny, możemy zobaczyć, gdy wygenerujemy na przykład 400 losowych trzypunktowych rozkładów prawdopodobieństwa, które następnie przedstawimy na wykresie trójkątnym (ang. ternary plot):
data<-gtools::rdirichlet(n = 400, alpha = c(1,1,1))
d.list <- split(data, seq(nrow(data)))
library(Ternary)
oPar <- par(mar = rep(0, 4), xpd = NA)
TernaryPlot()
TernaryPoints(d.list, pch = 16, cex = .5, col = "blue")
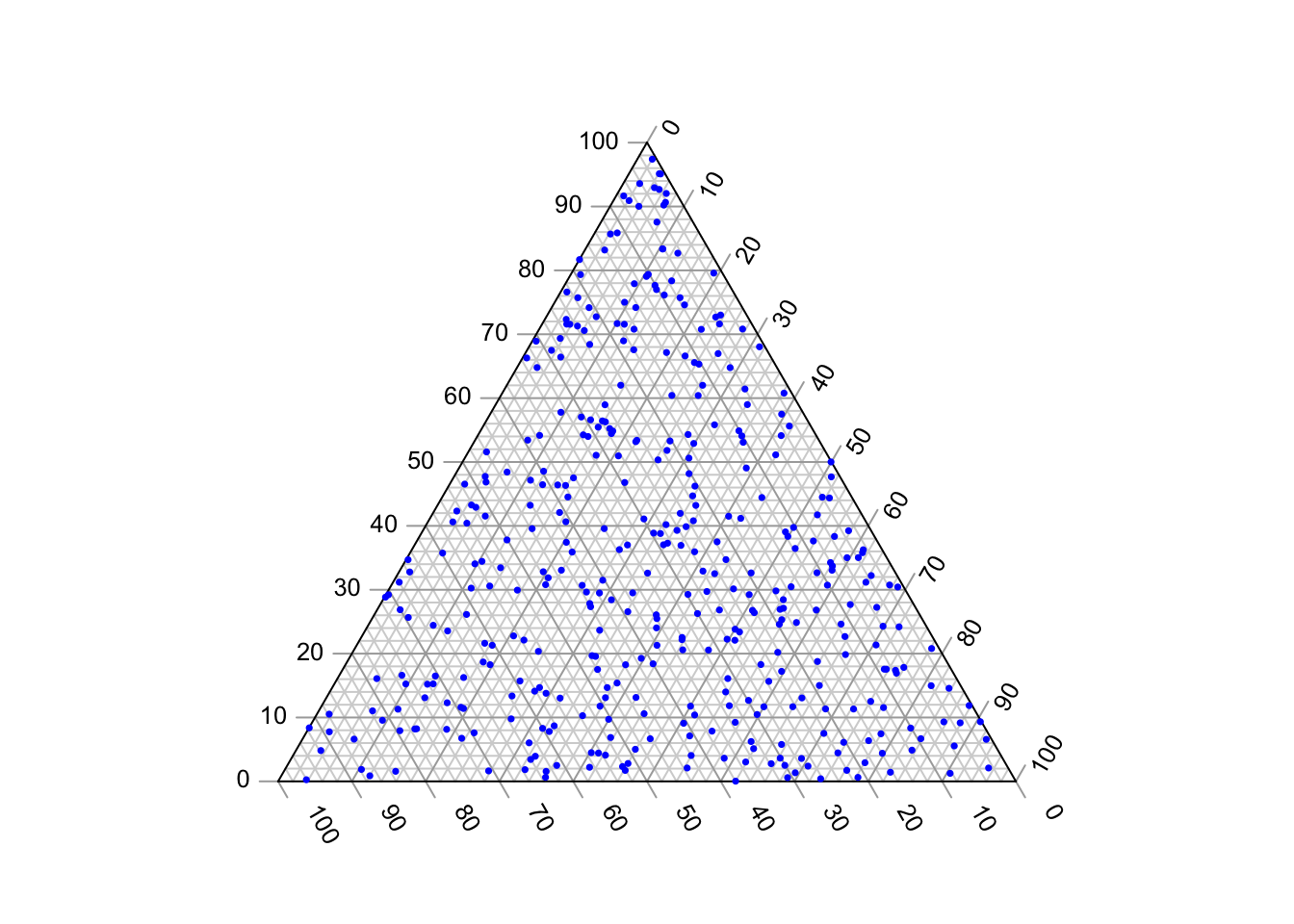
Jeżeli parametrom koncentracji nadamy wartość wyższą od 1, na przykład 3, punkty przedstawiające rozkłady prawdopodobieństwa będą koncentrować się w środku sympleksu, co oznacza, że mało prawdopodobne będzie uzyskanie niskich wartości prawdopodobieństwa.
data<-gtools::rdirichlet(n = 400, alpha = c(3,3,3))
d.list <- split(data, seq(nrow(data)))
oPar <- par(mar = rep(0, 4), xpd = NA)
TernaryPlot()
TernaryPoints(d.list, pch = 16, cex = .5, col = "blue")
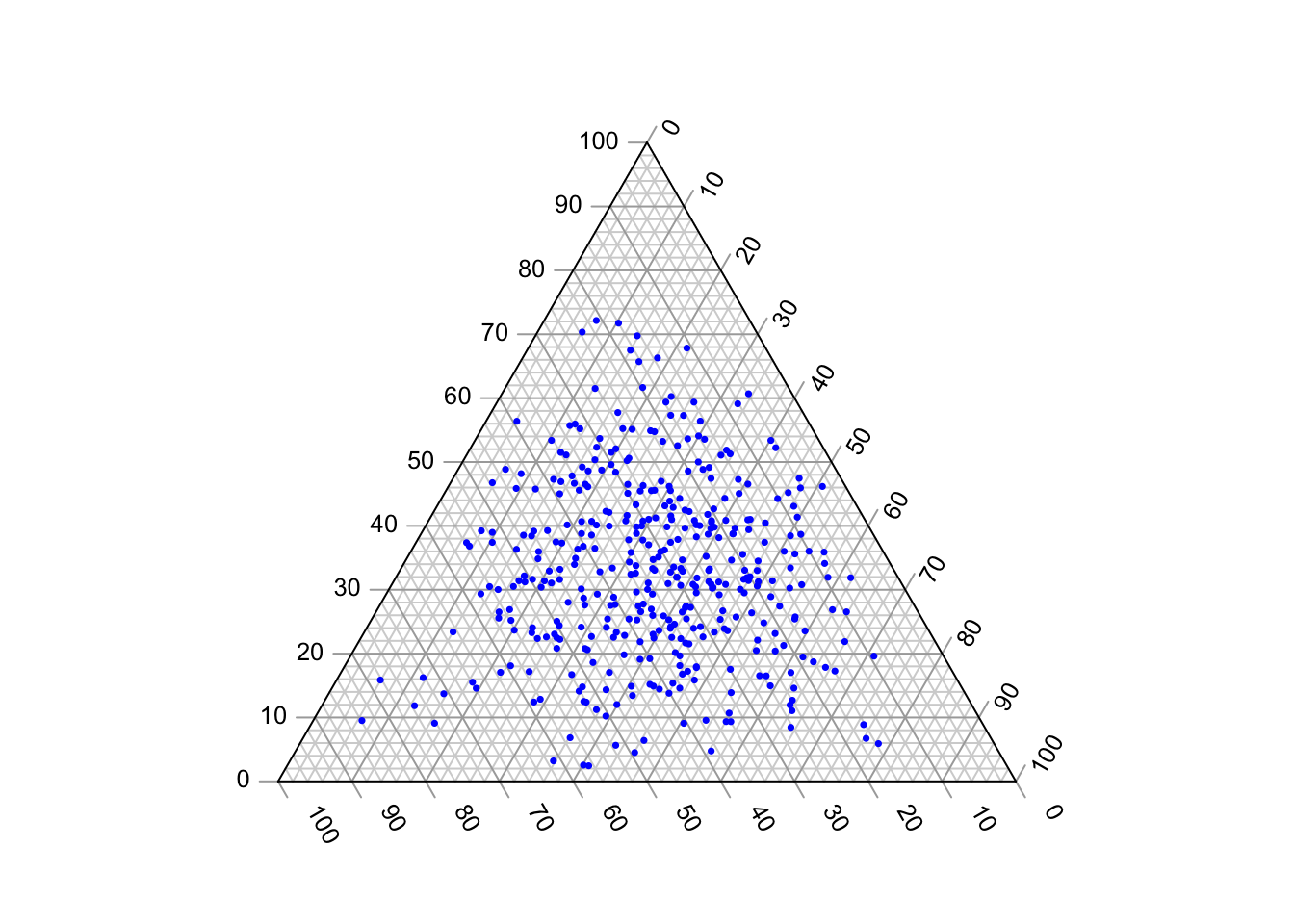
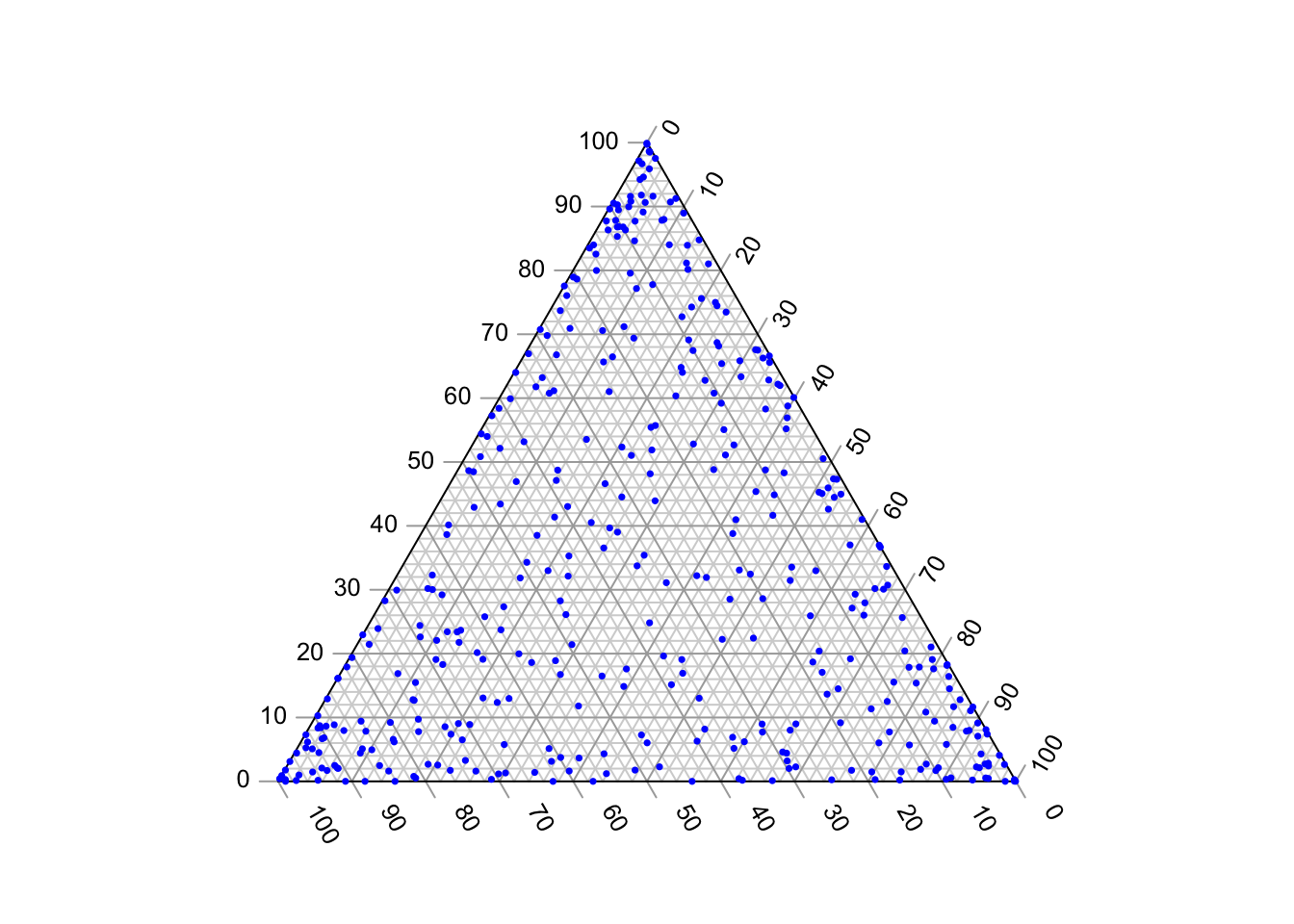
Jeżeli natomiast parametry koncetracji będą niższe niż 1, pojawi się tendencja do wylosowania przynajmniej jednego małego prawdopodobieństwa:
data<-gtools::rdirichlet(n = 400, alpha = c(1/2, 1/2, 1/2))
d.list <- split(data, seq(nrow(data)))
oPar <- par(mar = rep(0, 4), xpd = NA)
TernaryPlot()
TernaryPoints(d.list, pch = 16, cex = .5, col = "blue")
Uzbrojeni w te przykłady i intuicje, możemy wygenerować losowe zdania z wykorzystaniem pakietu exams. Plik Rmd generujący zadanie z losowymi liczbami może wyglądać na przykład tak (Plik można pobrać tutaj: example1.Rmd):
```{r data generation, echo = FALSE, results = "hide"}
# ustawienia
dm <- ','
options(scipen=999)
fin <- NULL
while (is.null(fin)) {
# losowanie trzech sumujących się do jedności prawdopodobieństw z rozkładu dirichleta
p <- gtools::rdirichlet(1, c(2, 2, 2))
# zaokrąglenia do dwóch miejsc po przecinku
p <- round(p, 2)
p[3] <- p[3] + 1 - sum(p)
x <- sample(1:9, 3) # losowanie trzech wartości
E <- sum(p * x) # wartość oczekiwana
V <- sum((x - E) ^ 2 * p) # wariancja
ans1 <- E
ans2 <- V
if (!any(any(p<.03), any(p>.97))) {
fin <- 1
}
}
```
Question
========
Pewna zmienna losowa $X$ przyjmuje przyjmuje trzy wartości:
- `r x[1]` z prawdopodobieństwem `r fmt(p[1], decimal.mark=',')`
- `r x[2]` z prawdopodobieństwem `r fmt(p[2], decimal.mark=',')`
- `r x[3]` z prawdopodobieństwem `r fmt(p[3], decimal.mark=',')`
Answerlist
----------
* Wartość oczekiwana zmiennej $X$ to:
* Wariancja zmiennej $X$ to:
Solution
========
`r options(OutDec=',')`
$$ E(X) = `r x[1]`\cdot`r p[1]` + `r x[2]`\cdot`r p[2]` +
`r x[3]`\cdot`r p[3]`= `r fmt(ans1,4)` $$
$$ V(X) = {(`r x[1]`-`r E`)^2\cdot `r p[1]`+(`r x[2]`-`r E`)^2\cdot
`r p[2]`+(`r x[3]`-`r E`)^2\cdot `r p[3]`} = `r V`$$
`r options(OutDec='.')`
Meta-information
================
exname: random_variable_example
extype: cloze
exsolution: `r fmt(ans1, 4)`|`r fmt(ans2, 4)`
exclozetype: num|num
extol: 0.0001|0.0001
Żeby testowo wygenerować zadanie w postaci html można uruchomić poniższy kod. Warto zauważyć, że za każdym razem w zadaniu powinny pojawiać się inne liczby i inne rozwiązanie.
exams::exams2html('example1.Rmd')
Dziesięć losowych zadań gotowych do załadowania na moodle można wygenerować za pomocą następującego kodu:
exams::exams2moodle('example1.Rmd', 10)
Stworzony w ten sposób plik xml można importować do Bazy pytań na moodle:

Następnie można losowe zadanie z tej puli wykorzystać w teście:


I gotowe!

Działa!
